Pandas Visual Analysis¶
Interactive visual analysis in Jupyter notebooks.¶
Installation¶
Using conda¶
To install this package with conda run:
conda install -c meffmadd pandas-visual-analysis
From Source¶
To install this package from source, clone into the repository or download the zip file and run:
python setup.py install
JupyterLab Support¶
Run the following commands to install the necessary JupyterLab extensions:
# plotly.py renderer support
jupyter labextension install jupyterlab-plotly
# Jupyter widgets extension for plotly.py
jupyter labextension install @jupyter-widgets/jupyterlab-manager plotlywidget
Note that this requires node to be installed!
Usage¶
Basic Usage¶
Having a DataFrame, for example:
import pandas as pd
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/mpg.csv"
df = pd.read_csv(url)
you can just pass it to VisualAnalysis to display the default layout:
from pandas_visual_analysis import VisualAnalysis
VisualAnalysis(df)
If you want to explicitly specify which columns of the DataFrame are categorical, just pass the categorical_columns option:
from pandas_visual_analysis import VisualAnalysis
categorical = ["name", "origin", "model_year", "cylinders"]
VisualAnalysis(df, categorical_columns=categorical)
Selection Types¶
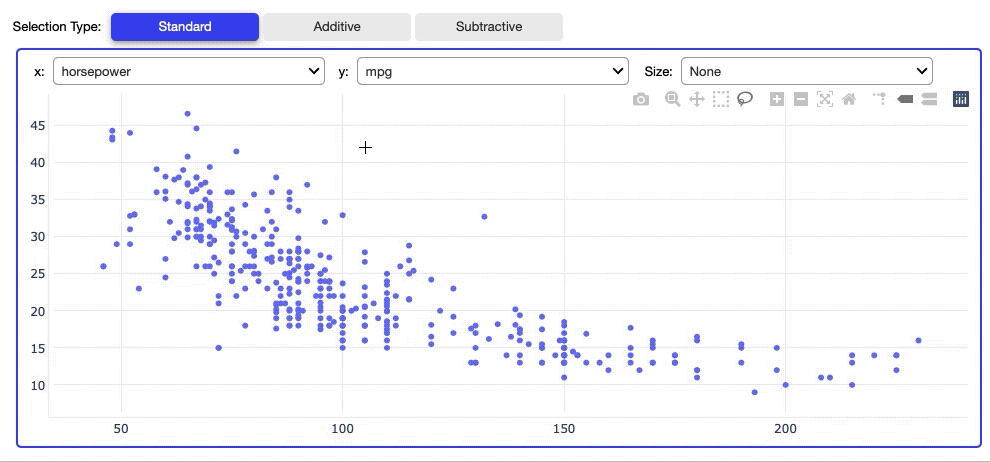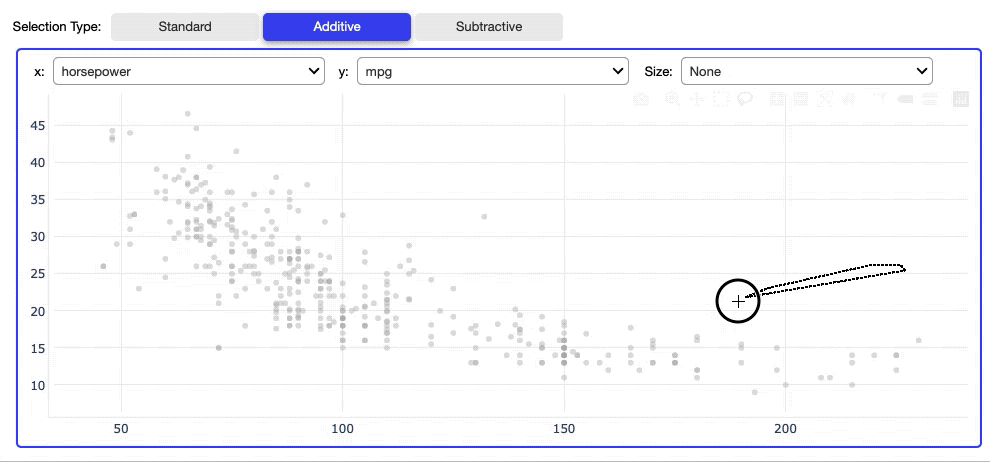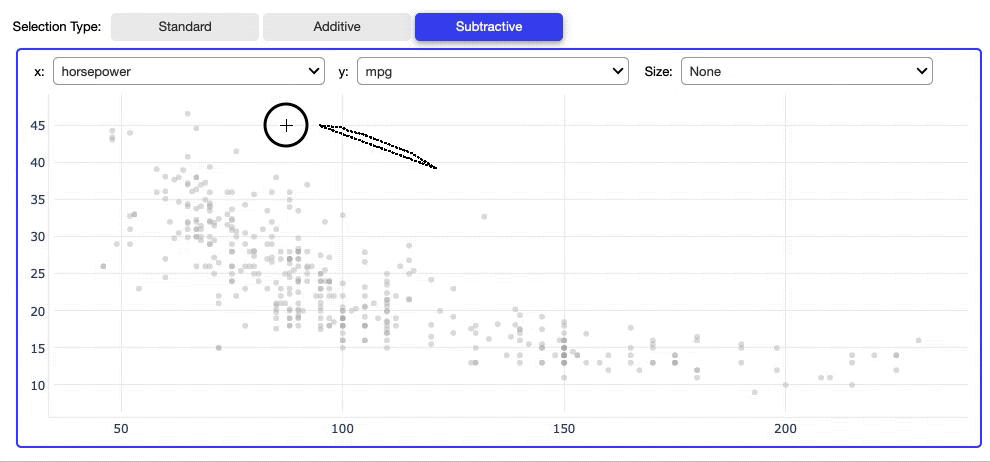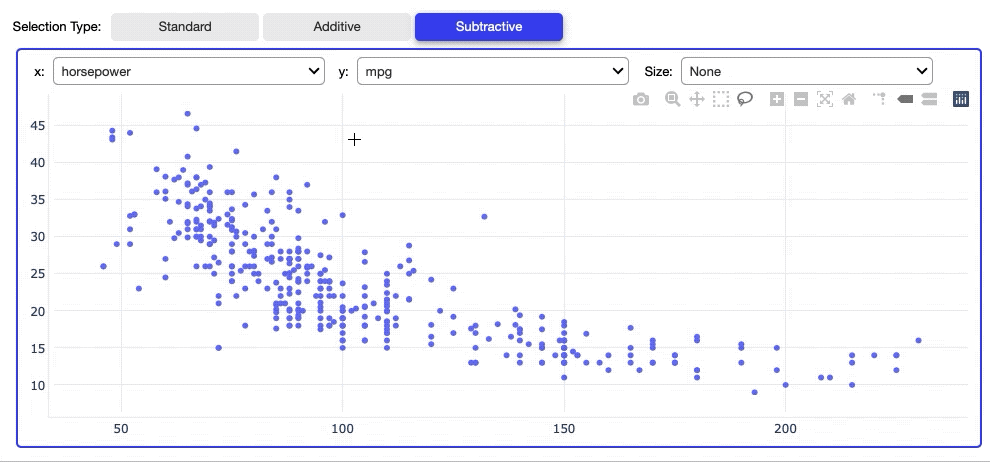
By default a new selection replaces the old selection, however, it is also possible to add data points to the existing selection by selecting the Additive selection type. By choosing the Subtractive selection, newly selected data points are removed from the selection.
Using DataSource¶
Instead of passing the DataFrame object directly to VisualAnalysis it is possible to use a DataSource object.
This enables linked-brushing across multiple notebook cells if the object is used across cells.
from pandas_visual_analysis import VisualAnalysis, DataSource
data = DataSource(df)
VisualAnalysis(data)
Later you can create a new analysis with the brushing still preserved
simply by using the same data object created earlier.
VisualAnalysis(data)
Using Layouts¶
If you want to specify your own layout, you can do that by passing the layout parameter.
The parameter is a list of rows, where each row is in turn a list specifying the Widgets in that row.
from pandas_visual_analysis import VisualAnalysis
VisualAnalysis(df,
layout=[["Scatter", "Scatter"],
["ParallelCoordinates"]]
)
Here, two scatter plots will share the first row while the second row only contains a parallel coordinates plot.
In order to see all the possible options you can call the widgets class-method of VisualAnalysis.
VisualAnalysis.widgets()
This outputs the following list of possible plots:
['Scatter',
'ParallelCoordinates',
'BrushSummary',
'Histogram',
'ParallelCategories',
'BoxPlot']
Any of those can be part of the layout specification. See also: widgets Documentation.
For more advanced features of the VisualAnalysis class see:
VisualAnalysis Documentation
Documentation¶
API Documentation